
REST, RESTful APIs, and API documentation
A dive-in on the most used architectural style to communicate between modern web applications!Table of Contents
Why do applications communicate between themselves?
As software complexity scales and many applications can have multiple features and requirements for users, interoperability between softwares are really useful to:
Separate concerns between modules and features
It allows us to divide our application into smaller, independent parts, making deployment and management easier when done the right way.
Scalability
It allows us to separate applications and services based on their responsibilities, ensuring that each module functions as it should.
Use features inside the app without the need to make it from scratch
Imagine, for instance, that we wanted to build an e-commerce platform. This alone includes numerous features to implement—payment processing being one of the most important. Interoperability allows us to integrate the platform with a payment gateway API.
This way, we can incorporate a critical feature—payment processing—into our software without needing in-depth knowledge of financial business rules, credit card operations, and other complexities.
A little bit of context
With the advent of public and private access to the internet, developers studied many ways to standardize the communication between softwares using the internet, mostly through RPC – Remote Procedure Call, which is a way to distributed systems to access remote code as if it is local, e.g using a library that another server hosts through a client.
One of the most popular of the standards was CORBA (Common Object Request Broker Architecture), which used a standard protocol called IIOP (Internet Inter-ORB Protocol). Using that protocol, CORBA could interoperate between CORBA-based programs across different vendors and programming languages by making RPCs from the client to a proxy that connects the code on the server, sending objects across the network so that those objects could be called remotely.
Such a standard can be complex to manage overt time due to its architecture, and scaling it can be really messy. Since it uses RPCs, both ends must agree on their interfaces, and any update to these interfaces implies in changing both sides. To do this, developers would have to spend a good amount of time implementing these changes.
In the late 90s and early 00s two standards created to interoperate softwares through web APIs surged, both utilizing the HTTP Protocol: SOAP (Simple Object Access Protocol), and REST (REpresentational State Transfer). These two standards are still in use today, although SOAP has been largely replaced by REST.
SOAP is an XML-based messaging protocol for exchanging information among computers, an application of the XML specification. It basically consists of sending a HTTP request with its verb and XML body containing the accepted tags defined in the application server. The application server will then process the request accordingly and return a response.
As for REST, it consists of sending an HTTP request with a verb and a body in either XML or JSON containing the attributes accepted by the application server. The server then processes the request accordingly and returns a response.
What is an API?
API stands for Application Programming Interface, and it can be defined as an interface that allows external entities to access a resource or perform an action within another application. Bear in mind that APIs are not exclusive to Web or distributed applications. Operating Systems are good examples of softwares that uses APIs too – Windows and Linux provide APIs that enable programs to allocate and manage hardware resources. In summary, APIs are a useful way to communicate with other applications.
What is REST?
REST stands for Representation State Transfer and according to its creator Roy Fielding, who presented the idea in his paper Architectural Styles and
the Design of Network-based Software Architectures, is:
A network-based architectural style derived from several others, with additional constraints that define a uniform connector interface.
So, REST is not a specific technology or a protocol, it’s an architectural style with a set of constraints that define a standard on how to structure a network-based application that can be accessed by external entities, be it a third-party software or a human being.
In Fielding’s paper REST is described as a derivation of several other styles, incorporating certain properties from these styles into REST as constraints except for the uniform interface constraint, since it is the central feature that distinguishes REST from other architectural styles.
In most cases, APIs that rely on REST as their architectural style transfer their data through HTTP or HTTPS requests, serializing the request body in JSON (JavaScript Object Notation) – a lightweight and easy for humans to read, data-interchange format.
Constraints
Client-server
The client server architectural style is probably the most known one and consists of two components:
- A server, which provides a set of services and resources, listens the requests and returns a response to whoever made that request.
- A client, which consumes these services and resources from the server, sends the request to the server and obtains the desired (or maybe not so much) response.
This is one of the pillars of distributed systems and most of the web applications follow this model, offering a very important concept to us: separation of concerns, dividing the application into two parts that can be managed, scaled and evolved independently. According to Fielding:
A proper separation of functionality should simplify the server component in order to improve scalability. This simplification usually takes the form of moving all of the user interface functionality into the client component.
We commonly see this in modern web applications in which the architecture is divided into Front End, and Back End. The Front End acts as the client interface that consumes or sends data, and the Back End acts as the server that processes the clients’ requests and returns the response accordingly, usually through HTTP/HTTPS requests.
Both components, when separated can be managed independently. It is important to note that both teams should have a clear communication over the contract changes that both ends needs to agree on.
Stateless
The stateless constraint requires that communication must be stateless in nature, meaning that each request must have all the data to be understandable by the server and, it cannot rely on any kind of stored state. This constraint improves:
Scalability:
Not relying on a shared context or a shared state makes it easier to scale our application, as there is no need to worry with an unpredictable behavior when managing a state in distributed servers. Additionally, it allows the server to free resources more quickly too.
Reliability
Each request is sent containing all the data that is needed to be processed by the server, making failures easier to identify and debug. These failures cannot occur due to a data specific shared state, but rather because of the data itself or how the server understands it, making one less of a variable to worry. And it makes easier to recover from partial failures.
Decoupling
Without a shared state the server no longer needs to know which component holds that state. Instead, it relies solely on the data provided by each request, and what the application can do with it, decoupling dependencies over this state.
Cache
This constraint consists of adding a cache component to the application that acts as a mediator between client and server, responding to the requests that are labeled as cacheable and returning the needed data to the client without reprocessing the request again on the server, reusing that data for future requests.
Cache can be used on both ends depending on the application architecture and needs. A common way to implement this constraint is using a In-memory database (e.g Redis, Dragonfly, AWS Memcache) to store reusable data and respond to every cacheable request without constantly interacting with the server.
A bad thing about cache though is reliability — sometimes the cache data can be stale, differing significantly from the data that would’ve been obtained from the server.
This contraint improves:
Performance
By caching reusable data, it reduces the response time since the data does not need to be loaded every time a request is made to the server, specially if it needs to load it from an external source (e.g API calls, database queries). Cache also reduces overhead from the application server by entirely or partially removing interactions to it.
Scalability
It allows us to add a cache service to every replicated node of the application server and still maintain the efficiency.
Uniform Interface
This is the central constraint that distinguishes REST from the other architectural styles. The principle behind uniform interface constraint is to use the concept of Interfaces – a generic kind of "contract" that two or more ends have to agree on in order to do something. In REST case, that something is to communicate with the application and retrieve, create, update or delete a resource.
Resources are the main entities in REST architectural style and we’ll see how they are managed further on. Uniform interface constraint is composed by four interface constraints (that is, four "contracts" in which the application must attend to, in order to obtain an uniform interface):
- Identification of Resources
- Manipulation of Resources through representations
- Self-descriptive messages
- HATEOAS – Hypermedia As The Engine of Application State
We’ll see about all these 4 constraints in Data Elements section
Layered Systems
This constraint involves designing the application architecture to consist of multiple layers that interoperate without generating side-effects and, ideally, without coupling each other.
By organizing the application into layers, we can separate the concerns and define clear boundaries between each one of them. Ideally this is done in a way that doesn’t make difficult to add more layers to the architecture. Some examples of layers are Load Balancers, Proxies, Middlewares and Third-party authentication services.
And it also improves scalability, since the application layers can be independently managed and scaled. This is pretty common to see in modern web apps, specially with the advent of cloud computing.
Code-on-demand
This is the only REST constraint that is optional, and in modern web applications, it is rarely implemented. It consists of allowing the client to download and execute code in form of applets or scripts.
Architectural Elements
Data elements
The table below shows what data elements are defined in REST:
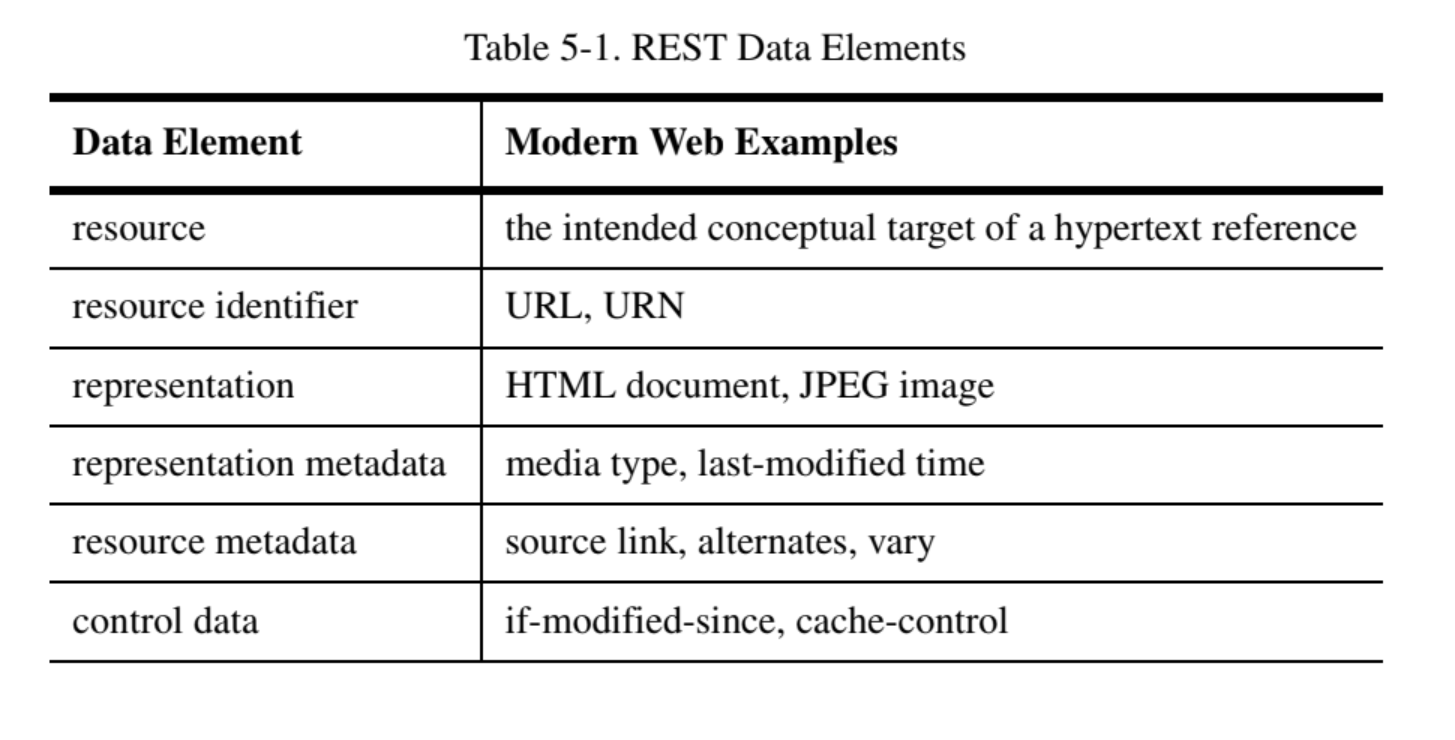
Resource and Resource Identifiers
In REST, information is represented as resources. A resource is any information that can be named, typically expressed as nouns, such as a collection of other resources, a file, an image, an entity (e.g books, albums, articles, etc.), and so on. Resources are the key architectural element in REST, due to the fact that all the other elements revolve around them.
According to Fielding:
Some resources are static in the sense that, when examined at any time after their creation, they always correspond to the same value set. Others have a high degree of variance in their value over time. The only thing that is required to be static for a resource is the semantics of the mapping, since the semantics is what distinguishes one resource from another.
For example – a resource called "Stephen King’s latest version of Dark Tower vol.3 release" could vary over time, making it a resource mapping that varies over time. Now, a resource called "The Dark Tower Vol. 3 2012 edition release" is a static resource mapping. Although, they reference the same data, they are distinct resources, and should be identified distinctively.
These resources are identified using a URI (Uniform Resource Identifier) – which is a formal system for uniquely identifying resources. URIs consists of two types: URLs (Uniform Resource Locator) and URNs (Uniform Resource Name). The most commonly used type is the URL.
Representation
Since one of REST’s core characteristics is statelessness, the way to manipulate resource’s data is through its representations. These representations capture the current or intended state of a resource, and this is how operations are handled within REST APIs. Representations also includes metadata. In the case of HTTP / HTTPS requests, a common type of metadata is the "Content-Type" attribute. For example, for JSON body responses and requests, the Content-Type is typically "application/json". Below is an example of a JSON representation of a user profile.:
{
"user": {
"id": 1,
"name": "Joseph",
"email": "joseph@email.com"
},
}Connectors
Connectors encapsulate the activities of accessing resources and transferring resource representations.

Components
REST components are separated based on their roles in an overall application action. These components can be summarized in the table below:

Origin server: The definitive source for representations of its resources. Usually it’s the application server.
Gateway: A mediator responsible for connecting two different networks or protocols, acting as a bridge between two different systems. One common use is as an API Gateway — a gateway that manages and routes API requests, authentication, etc.
Proxy: A mediator that acts as a "filter" for requests, forwarding client requests to the appropriate server. A common use for proxy is as a reverse proxy – a proxy that receives requests and direct them to other servers hosting the same application, providing load balancing and enhanced security.
User agent: The application consumer. Usually web browsers.
Hypermedia As The Engine Of Application State
Hypermedia As The Engine Of Application State (HATEOAS) is a constraint that adds a layer of navigability within a REST service, allowing a client to interact with the service through provided links that serves as guides to access other endpoints from a resource.
Here’s an example of an endpoint response from a user’s profile with HATEOAS applied:
{
"user": {
"id": 1,
"name": "Joseph",
"email": "joseph@email.com"
},
"links": [
{ "rel": "self", "href": "/users/1" },
{ "rel": "friends", "href": "/users/1/friends" },
{ "rel": "posts", "href": "/users/1/posts" }
],
"actions": [
{ "rel": "followUser", "href": "/users/1/follow", "method": "PUT" }
{ "rel": "unfollowUser", "href": "/users/1/unfollow", "method": "PUT" }
{ "rel": "blockUser", "href": "/users/1/block", "method": "PUT" }
]
}
Practice
But how can all these constraints be applied?
REST APIs use standard HTTP methods to perform Create, Read, Update and Delete (CRUD) operations on resources, which are identified through URLs.
To execute perform these operations we rely on different HTTP methods:
Create
This type of operation creates new representations of a resource, and uses the POST HTTP method in requests. The data required to create the resource is included in the request body.
Read
This type of operation retrieves a representation of a resource data, and uses the GET HTTP method in requests. GET requests MUST NOT create or update a resource, and preferably, should not accept a request body.
Update
This type of operation updates entirely or partially a representation of a resource’s data. For partial updates it is used the PATCH HTTP method, while for total updates it is used the PUT HTTP method. The resource to be updated is usually identified through parameters in the URL, and the data required to update the resource is included in the request body.
Delete
This type of operation deletes a resource’s representation, and uses the DELETE HTTP method on the request. The resource to be updated is usually identified through parameters in the URL.
Additionally, we have two interesting HTTP methods that do not perform any of the transactions mentioned above, but are useful for retrieving information from REST APIs: the HEAD and OPTIONS methods. The HEAD method is used to ask if a given resource exists without returning any of its representations, while the OPTIONS method is used to retrieve a list of available verbs on a given resource.
After processing a request, response status codes are returned by the server, indicating success or failure:
- 2XX Codes indicates success
- 3XX Codes indicates redirect
- 4XX Codes indicates a client error
- 5XX Codes indicates a server error
Example
To better illustrate these operations, let’s see an actual example of an API, a bookstore web API. Here would be our overall structure:
| Http Method | Endpoint | Action | Response |
|---|---|---|---|
| GET | /books | Retrieves all books. | 200 – Ok |
| GET | /books/:id | Retrieves a specific book through an unique identifier. | 200 – Ok |
| POST | /authors | Creates a new author. | 201 – Created / 422 – Unprocessable Entity (when data is invalid) |
| GET | /authors | Retrieves all authors | 200 – Ok |
| GET | /books/:id/authors | Retrieves all authors from a specific book. | 200 – Ok |
| POST | /books | Creates a new book. | 201 – Created / 422 – Unprocessable Entity (when data is invalid) |
| PATCH | /books/:id | Partially updates a book’s data, like title, isbn, etc. | 200 – Ok / 422 – Unprocessable Entity (when data is invalid) |
| PUT | /books/:id | Adds a new related resource to a book, like another author, or another book image. | 200 – Ok / 422 – Unprocessable Entity (when data is invalid) |
| GET | /books/:id/images | Retrieves all images from a specific book. | 200 – Ok |
| POST | /books/:id/cover_image | Creates a new cover image to a book. | 201 – Created / 422 – Unprocessable Entity (when data is invalid) |
Note that all of these actions and endpoints are CRUD operations. But what about non-CRUD ones?
Non-CRUD operations are really common in REST APIs, there are typically a few approaches to handling them:
Render an action as part of a resource’s field
For example, if we wanted to block a user from our store for some obscure reason, it could be done like so:
PATCH /users/:id
HOST localhost:3000
Content-Type: application/json
Authorization: Bearer TOKEN
{
"blocked": true
}Treat an action like a sub resource
For example, our bookstore api could allow users to create both public and private lists, enabling them to favorite other users’ lists. This could be available through the POST /users/:id/lists/:id/favorite endpoint.
Name the endpoint as a verb
A good example on this approach is when it’s needed to search for a specific resource representation, such as GET /books/search/:book_name. A good way to implement this is by using query parameters, like so: /books/search?q=designing%20web%20apis. This approach is an effective way to handle complexity in the URL.
Good Practices
Make it Fast and Easy to Get Started
The most important thing about an API is how easy it is to use it and integrate it with other softwares (remember, APIs are all about communicating between systems).
To make an API developer-friendly, it’s essential to provide clear and accessible documentation. We’ll see details of a specification that standardizes documenting web APIs, but keep in mind that documentation can go beyond that, from detailed specifications and organized pages, guides, demonstrations and tutorials, to interactive sandboxes and SDKs (Software Development Kits).
These are just some examples of resources that can create a much better experience to the developers, specially when the API requires some sort of authentication process.
Work Towards Consistency
Working to make the endpoint names, input parameters and output responses more consistent helps to build an API that’s more intuitive to use, building patterns throughout the API that makes easier for the developers to predict some endpoints’ usage, minimizing cognitive load over them, allowing them to use your API effectively. Doing so it simplifies code maintenance too:
- Inconsistencies, such as varying data types for the same field or two different names to the same resource, can lead to confusion and extra work for developers, who then need to implement additional logic adapting their code base to that messy interface. Removing these inconsistencies (specially when it’s a duplication of knowledge) makes easier for developers to create simpler code.
Make it Easy to Troubleshoot
Make easy to troubleshoot is essential, letting the developers know what went wrong and how can they act upon this error is crucial to improve and maintain a system. This can be done by:
Returning meaningful errors:
Errors could originate from business logic error, a bad database connection, something specific from the server, and many other sources. This variety can make troubleshooting difficult depending on how the error it’s structured, and errors are organized within the application. That’s why it is so important to systematically organize and categorize these errors, making them meaningful.
Meaningful errors should be easy to understand, unambiguous and actionable – providing clear details about what really went wrong, along with its context. For example, errors should be categorized to distinguish between database errors, business logic errors, and other types, along with a description of the specific issue (e.g., what caused the failure).
Also, the HTTP status codes should be used properly when returning these errors. You wouldn’t want to return an error response that occurred due to a invalid data that came from a form, with a 502 Bad Gateway status code. That doesn’t make sense.
Build Tooling
Build tooling is an effective way to make troubleshooting easier for both internal and external developers, by building internal and external tools that can help with that. Tools such as logging, monitoring and analytic platforms.
Logging and monitoring are downright essential to your API’s health – it helps identify when something goes wrong, or when some endpoint could have its performance improved somehow. Analytics platforms, for example, can be used to identify unused parameters on an endpoint, triage common errors, and aggregate many other metrics that could help to improve the API.
Make Your API Extensible
The need to make APIs extensible comes from the fact that in most cases there’s always a change that modifies a feature and its usage, breaking any application that’s not adapted to these changes. They are called breaking changes.
Extensibility is about evolving your API so that it minimizes the impact on external developers, easing their suffering when dealing with breaking changes. To achieve this, we can use the strategy of API versioning. Versioning allows external developers to access the API through different versions (e.g api/v3/some_resource), isolating breaking changes between versions. This ensures that developers using an older version won’t need to immediately adapt their code base to that change as soon as possible, giving them more reliability and time to plan future updates.
The bad thing is that can it be difficult to maintain different versions of the same API in production depending on its complexity, especially if it wasn’t designed with that in mind. If there aren’t that many changes released to your API, maybe versioning it doesn’t make much sense.
Documentation
Picture yourself being an electrician, and your task it’s to give maintenance to a shopping mall’s electrical wire system. But here’s the thing – the mall doesn’t have any kind of building plan whatsoever – so everything that you will perform is going to be based solely on your empirical understanding of that system. Sounds insane, right? That’s the importance of having any kind of knowledge base – a documentation.
Documentation serves the same purpose as a building plan or a map – it offers you guidance throughout the whole system, allowing other developers to get involved in the project more easily, letting them to know the API’s capabilities and features. It makes debugging way more easier.
And for that purpose we use Swagger and the OpenApi Specification.
OpenApi
According to OpenApi’s official specification page:
The OpenAPI Specification (OAS) defines a standard, language-agnostic interface to HTTP APIs which allows both humans and computers to discover and understand the capabilities of the service without access to source code, documentation, or through network traffic inspection. When properly defined, a consumer can understand and interact with the remote service with a minimal amount of implementation logic.
So the idea is to describe the API’s elements such as resources paths and its requests, and responses structures, in a document that conforms to the OpenApi Specification. This document can be either in JSON or YAML format. The goal is to have a web interface that serves as a kind of "playground", enabling users to make requests to the server and to check the possible responses accordingly.
There are a lot of keys that are used on this document but the mains are:
- info: Metadata about the API, such as title and description.
- paths: Relative paths to the individual endpoints and their operations.
- components: Reusable objects such as schemas, request parameters, examples and responses.
- tags: Endpoints organization.
- servers: Server representation.
- schema: It defines the structure and data types of both the request and response of an endpoint.
Example:

The document looks like this:

[^]: Note that the schema for some request bodies and responses is being defined with $ref: '#/components/schemas/Pet'. This is how components are used within the document, in this case, there are reusable schemas that are defined inside components key.
And this is only a small part of that document (that you can check it out here).
THANKFULLY, we don’t need to create all this structure from scratch. Today we have libraries such as RSwag for Ruby and Swagger JSDoc for NodeJS. These libraries generates the document that we need, based on the endpoints that we have within the application.
In this case we’ll use RSwag.
RSwag
RSwag is a Ruby gem that extends RSpec by integrating it with Swagger. It helps generate interactive API documentation and automate the testing of APIs.
Let’s see an example of that:

RSpec is able to use that DSL due to the swagger_helper.rb file. That helper is responsible for setting up the swagger file location along with its format, plus any extra configuration that you might add to use within the tests.
One important thing to note is that the components, infos, servers and paths (optionally, since we can define the paths within the tests) are defined in that helper file. Here’s an example of the album schema:

To generate swagger document we run the command RAILS_ENV=test rails rswag. Here’s the swagger document generated:

And here’s the web UI:

That POST /albums endpoint in Swagger UI looks like this:

References
https://greglturnquist.com/2016/05/03/rest-soap-corba-e-got/
https://chelseatroy.com/2018/08/01/api-design-part-1-before-there-was-rest/
Previously in the TMGCC: Code review and team communication
Next Up: JavaScript Beginner’s Guide
This post is part of our ‘The Miners’ Guide to Code Crafting’ series, designed to help aspiring developers learn and grow. Stay tuned for more and continue your coding journey with us!! Check out the full summary here!
We want to work with you. Check out our Services page!
Share
 Jonathan Ribeiro
Jonathan Ribeiro Let's build a scalable frontend that grows with your business.
Contact Us

