
Cinco Coisas Que Seu Agente de IA Gostaria Que Você Soubesse
Table of Contents
Vejo a mesma frustração em todos os lugares – Reddit, Discord, Twitter. Alguém diz para o agente de código seguir um padrão específico, o agente acerta na mosca, e cinco prompts depois, age como se a conversa nunca tivesse acontecido. "Por que ele fica esquecendo?" "É um bug?" "Eu literalmente acabei de falar isso."
Não é um bug. É a compressão de contexto fazendo exatamente o que deveria fazer. Mas a maioria das pessoas usando agentes de código – Claude Code, OpenCode, Cursor, Cline – não faz ideia do que está acontecendo por baixo dos panos. Tratam os agentes como caixas pretas. Caixas pretas mágicas.
Eles não são mágicos. Nem são tão complexos assim. E quando você entende os poucos conceitos centrais por trás deles, para de brigar com a ferramenta e começa a tirar muito mais proveito dela.
1. Tudo é prompting
Se você levar uma coisa deste post, que seja esta.
Todo comportamento que você vê de um agente de código – cada “funcionalidade”, cada “habilidade”, cada “traço de personalidade” – é resultado de um prompt. Um prompt do sistema que você nunca vê, mas que está lá, moldando cada resposta.
Quando o Claude Code se mostra opinativo sobre estilo de código, isso é um prompt. Quando pede confirmação antes de executar comandos destrutivos, isso é um prompt. Quando formata respostas de determinada forma, isso é um prompt.
Não existe motor de raciocínio oculto. Nenhuma arquitetura especial de agente está fazendo algo fundamentalmente diferente do que acontece quando você digita numa janela de chat. É um LLM recebendo texto e gerando texto. A parte “agente” é um loop: fazer prompt ao modelo, processar a saída, executar chamadas de ferramentas, alimentar os resultados de volta, repetir.

Isso importa porque quando você internaliza isso, percebe que você pode influenciar o comportamento do agente da mesma forma que o prompt do sistema faz – escrevendo instruções melhores. Seu arquivo CLAUDE.md, seus prompts, suas correções no meio da conversa – tudo faz parte do mesmo mecanismo. Você não está “configurando” o agente. Você está fazendo prompting nele.
Aqui está como uma sessão real do Claude Code se parece por dentro. Esta é a saída do comando /context – mostra exatamente o que está ocupando a janela de contexto:
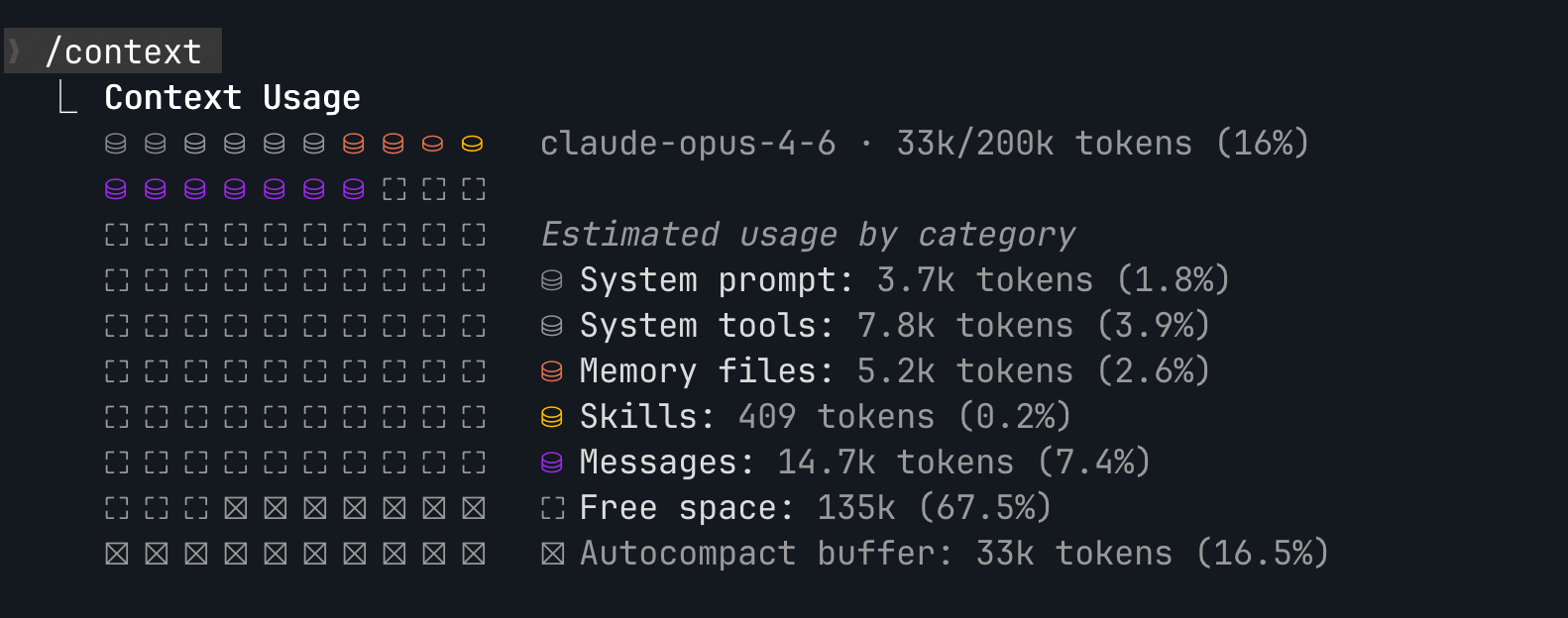
Prompt do sistema, ferramentas do sistema, arquivos de memória, habilidades, mensagens. Só isso. Esse é o agente inteiro. Texto entra, texto sai. Cada categoria que você vê ali é apenas texto sendo alimentado ao modelo antes de gerar uma resposta.
2. Tools são apenas funções descritas em texto
Quando um agente de código lê um arquivo, executa um comando shell, ou busca na sua base de código, não está usando alguma API interna privilegiada. Está chamando uma ferramenta. E uma ferramenta, da perspectiva do LLM, é apenas uma descrição JSON de uma função.
O modelo vê algo como: “Existe uma ferramenta chamada Read que recebe um parâmetro file_path e retorna o conteúdo do arquivo.” Só isso. O modelo decide quando chamá-la, gera os parâmetros, e o runtime do agente executa a função real e alimenta o resultado de volta.
Isso é importante porque o modelo só pode usar tools que conhece. Se uma ferramenta não está descrita no prompt, ela não existe para o modelo.
No Claude Code, tools centrais como Read, Edit, Bash, e Grep são sempre carregadas no contexto. Você pode vê-las na saída do /context ocupando 8k tokens. Ferramentas MCP – integrações que você adiciona, como Figma ou Slack – também são carregadas por padrão. Mas isso cria um problema: se você tem dezenas de ferramentas MCP, suas descrições começam a comer sua janela de contexto antes mesmo de começar a trabalhar.
O Claude Code resolve isso com carregamento sob demanda. Você pode controlar com a variável de ambiente ENABLE_TOOL_SEARCH (definida como auto por padrão, que ativa quando descrições de ferramentas MCP excedem 10% do contexto). Quando carregamento sob demanda está ativo, todas aquelas descrições individuais de ferramentas MCP são substituídas por uma única ferramenta: ToolSearch.
Pense como substituir um menu longo por uma barra de busca. O modelo não vê mais “ferramenta de screenshot do Figma, ferramenta de metadados do Figma, ferramenta de enviar mensagem do Slack…”. Ele vê: “existe uma ferramenta ToolSearch que você pode chamar para encontrar ferramentas disponíveis.” O prompt do sistema diz ao modelo que ferramentas adiadas existem e que ele deve buscar antes de chamá-las. O modelo não sabe quais ferramentas estão disponíveis, mas sabe que algo está lá e como descobrir.
Então quando você pede ao agente para tirar um screenshot do Figma, ele chama ToolSearch com algo como “figma screenshot”, o runtime busca através de todos os nomes e descrições de ferramentas MCP registradas, e a ferramenta correspondente é carregada no contexto. Só então o modelo pode realmente chamá-la. Seus servidores MCP ainda estão configurados em .claude/settings.json – o runtime conhece todos eles, mas o modelo só vê os que busca explicitamente.
Saber disso explica muito comportamento “estranho”. O agente não usou a ferramenta certa? Talvez não soubesse sobre ela. O agente chamou uma ferramenta com parâmetros errados? Está adivinhando a partir de uma descrição de texto, não de verificação de tipo. O agente continua usando cat em vez da ferramenta dedicada Read? Seu prompt diz para não fazer isso, mas é um modelo probabilístico – às vezes deriva.
3. Habilidades são ferramentas que você define
Vê o padrão? Ferramentas centrais estão sempre em contexto. Ferramentas MCP podem ser carregadas sob demanda via ToolSearch. Habilidades seguem exatamente o mesmo padrão – são apenas ferramentas, mas que você define.
No Claude Code, habilidades costumavam ser chamadas de “comandos.” Mudaram o nome, mas o mecanismo é o mesmo. Você cria um arquivo markdown em .claude/skills/, escreve instruções nele, e o agente trata como uma ferramenta que pode chamar.
Funciona assim. No início da sessão, descrições de habilidades (o resumo curto do frontmatter) são carregadas no contexto – então o modelo sabe quais habilidades existem. Você pode ver isso na saída do /context: “Skills: 409 tokens.” Mas o conteúdo completo da habilidade não carrega até ser invocado. Quando você digita /commit, o modelo chama uma ferramenta interna Skill, que busca o arquivo markdown completo e o injeta no contexto. O modelo então segue essas instruções.
Mesmo mecanismo que ToolSearch. Mesmo mecanismo que o prompt do sistema. É tudo apenas texto sendo carregado no contexto em momentos diferentes.
Você pode criar suas próprias habilidades. Escreva um arquivo markdown com instruções, coloque em .claude/skills/, e o agente pega. Quando digito /title-generator, o modelo chama Skill, carrega meu arquivo markdown personalizado que diz “dado um tópico, produza 5+ opções de título em diferentes estilos usando essas fórmulas de manchete…”, e segue. Não é diferente de uma habilidade interna.
A diferença entre uma “funcionalidade interna” e sua habilidade personalizada é apenas onde o texto fica. Habilidades internas vêm com a ferramenta. As suas ficam no seu projeto. O LLM as trata exatamente da mesma forma. É prompting até o fim.
4. Memória não é o que você pensa
É aqui que mora a maior parte da confusão.
As pessoas assumem que agentes de IA têm memória como humanos – que coisas ditas anteriormente numa conversa são “lembradas” como você lembra do que comeu no café da manhã. Não são.
Um LLM não tem estado persistente entre chamadas. Cada vez que o modelo gera uma resposta, processa a conversa inteira do zero. O que parece “memória” é na verdade o histórico da conversa sendo enviado como parte do prompt toda vez.
Isso tem um limite rígido: a janela de contexto. Para o Claude, são cerca de 200K tokens. Parece muito, mas resultados de ferramentas se acumulam rápido. Leia alguns arquivos, execute alguns comandos, e você já queimou uma boa parte.
O que acontece quando o contexto se enche
O agente comprime mensagens mais antigas. Resume ou descarta partes da conversa para abrir espaço para conteúdo novo. É por isso que agentes “esquecem” suas instruções – foram comprimidas.
Isso não é um bug. É uma troca de design. A alternativa é que a conversa simplesmente pare.
Memória de longo prazo
Compressão de contexto é um problema. Se o agente esquece suas instruções no meio da conversa, você precisa de uma forma de fazer as coisas grudarem. É para isso que serve a memória de longo prazo.
No Claude Code, existe um diretório memory/ onde o agente escreve notas que persistem entre conversas. Carrega esses arquivos no início de cada sessão. Aqui está como fica:

CLAUDE.md é seu arquivo de instruções do projeto – convenções de código, decisões de arquitetura, coisas que o agente deveria sempre saber. MEMORY.md é onde o agente armazena coisas que aprendeu durante conversas anteriores – padrões que confirmou, preferências que você corrigiu, decisões que vocês tomaram juntos.
Ambos são injetados no prompt do sistema. Ambos são apenas arquivos de texto no disco.
O que isso significa para você
Se você disser algo crítico ao agente no meio da conversa, pode ser comprimido depois. Mas se estiver nos seus arquivos de memória, estará lá no início de cada conversa.
Mantenha seus arquivos de memória atualizados. Só isso. Coloque suas convenções de código no CLAUDE.md. Deixe o agente salvar padrões e decisões no MEMORY.md. Quando corrigir o agente em algo, diga para ele lembrar. Não confie em correções no meio da conversa esperando que grudem – escreva onde seja carregado toda vez.
5. Contexto é tudo (literalmente)
O que o agente produz depende inteiramente do que está no seu contexto. Isso soa óbvio, mas as implicações não são.
O agente não “conhece” sua base de código. Conhece quaisquer arquivos que leu na sessão atual. Se faz uma suposição errada sobre sua arquitetura, provavelmente é porque ainda não leu os arquivos certos.
É por isso que bons agentes leem antes de escrever. E é por isso que você deveria desconfiar quando um agente propõe mudanças em código que não olhou.
Algumas consequências práticas.
Conversas longas se degradam. Conforme o contexto se enche e comprime, o agente perde informação anterior. Comece conversas novas para tarefas novas.
Não assuma que o agente “sabe” algo de três chamadas de ferramenta atrás. Se é importante, reafirme ou coloque nas suas instruções de projeto.
Carregue seu contexto na frente. O início da conversa e o prompt do sistema recebem mais “atenção” do modelo. Coloque suas restrições mais importantes lá.
Por que isso importa
Você não precisa fazer nada miraculoso para obter resultados eficazes de agentes de código. Não precisa dominar frameworks de engenharia de prompt, ler todos os papers sobre arquiteturas de LLM, ou fazer engenharia reversa de prompts do sistema.
Você precisa entender o básico. Só isso.
Contexto é uma janela com limite de tamanho, e coisas são descartadas quando se enche. Ferramentas são descrições de texto que o modelo lê e decide chamar. Habilidades são ferramentas que você mesmo escreveu. Memória são arquivos no disco que são carregados no início. Tudo é prompting.
Este é seu princípio de Pareto para agentes de IA. Esses cinco conceitos são os 20% que resolvem 80% dos seus problemas. Quando o agente esquece algo, você sabe por quê – compressão de contexto. Quando não usa a ferramenta certa, você sabe por quê – não foi carregada. Quando ignora suas convenções, você sabe o que fazer – atualizar seu CLAUDE.md.
A maioria das pessoas está lá fora brigando com a ferramenta porque pularam os fundamentos. Querem técnicas avançadas quando não entenderam o básico. Já vi esse padrão antes no desenvolvimento de software, e nunca termina bem. Você não pode debugar o que não entende.
Entender como a máquina funciona sempre é o primeiro passo. Era verdade antes dos agentes de IA, e é verdade agora.
Obrigado por ler!
We want to work with you. Check out our Services page!
Share
 Edy Silva
Edy Silva Let's build a scalable frontend that grows with your business.
Contact Us

